Stop Prompting. Start Building Software Factories for Java
with Ingo EichhorstIngo Eichhorst joined me to show a practical Software Factory workflow for Java: define quality first, add hard guardrails, and let AI implement inside those boundaries.

YouTube
Stop Prompting. Start Building Software Factories for Java
Load YouTube video
This video is embedded from YouTube and will only be loaded after your consent. When loading it, personal data may be transmitted to YouTube or Google and cookies may be set.
More details are available in the privacy policy.
Project Source
Working Repository
Explore prompts, instructions, and examples used in the live modernization workflow.
Open repositorySession Timeline
- 00:00Welcome and Introduction
- 00:52Topic Overview: Software Factories
- 01:01Guest Introduction: Ingo Eichhorst
- 02:04Ingo's Background and Journey
- 05:25Ingo's Pivot to AI and Generative Models
- 06:00Early AI Coding Experiments and Tools
- 11:04Defining Software Factories
- 13:41The Concept of Non-Deterministic Idempotency
- 14:09Software Factory Automation Approach
- 15:44Vision of the Dark Factory
- 21:57Basic Principles of Software Factories
- 23:44Defining Quality in Software Factories
- 27:22Introduction to the Eichhorst Principle
- 31:11Applying Shannon's Theory to LLM Communication
- 40:36Overview of the Ehrlicht Project
- 46:15Starting the Coding Session: Quanta Project
- 49:42Reviewing Tests and Feedback Mechanisms
- 55:22Specifying Requirements for New Endpoint
- 58:06Using LLM for Clarifying Questions
- 01:00:46Discussion on Chat Interface Features
- 01:06:07Summarizing Requirements in a PRD
- 01:09:28Creating and Adding Acceptance Criteria
- 01:14:28Building the Feature and Git Good Practices
- 01:25:23Thoughts on Test-Driven Development with LLMs
- 01:29:02Using Regression Tests in AI Development
- 01:34:09Testing Costs and Strategy
- 01:35:58Running Docker and Project Setup
- 01:42:44Glossary: Loop Engineering and Related Terms
- 01:51:11Review of Integration Tests and Codebase
- 01:55:23Using Git Worktrees for Multiple Agents
- 02:00:03Testing Strategy: Shift Left Approach
- 02:03:33Automated Release Testing
- 02:06:31Concluding Thoughts on Software Factories and AI
- 02:09:53Closing Remarks and Thanks
AI can write code quickly. Most of us have seen that by now.
The harder question is this: how do we get good results repeatedly, not just once in a lucky run?
That was the center of this session with Ingo Eichhorst. We explored Software Factories for Java in a practical way: define quality first, build tight feedback loops, and let AI implement inside those boundaries.
It was also my first stream organized with JUG Oberpfalz, which made the session even more meaningful for me.

Co-Speaker
Ingo Eichhorst
AI Architect | Engineering Trainer at IONOS
Ingo is an AI architect and engineering trainer at IONOS and the maintainer of irrlicht.io. He brought a clear systems thinking perspective to AI-assisted software delivery and introduced the Eichhorst Principle during the session.
From Prompting To Factory Thinking
The most useful idea from the evening was not a new tool, model, or coding trick. It was a shift in what to optimize for.
A Software Factory is not mainly about asking AI better questions. It is about building a delivery system that can produce the desired result repeatedly. That means the center of gravity moves away from prompting and toward engineering discipline: clear specifications, measurable acceptance criteria, layered tests, and automated checks.
That distinction matters because it changes how you judge AI output. The question is no longer whether the answer looks plausible. The question is whether the change survives the system around it.
Quality Gates Are The Real Product
The session kept returning to one practical point: if you want reliable AI-assisted development, the most important work often happens before and after generation.
Before generation, you need to define the shape of a good result. After generation, you need a receiver that can reject weak output automatically. In practice, that receiver is a stack of quality gates: acceptance tests, unit tests, integration tests, linting, and CI/CD.
That is also why this session felt more useful than a generic live coding demo. It framed AI less as an autonomous author and more as a component inside a controlled system.
The Eichhorst Principle Makes The Failure Modes Visible
The strongest conceptual contribution came from Ingo's use of Claude Shannon's communication model. The Eichhorst Principle applies that model to AI-assisted software delivery and gives you a concrete way to reason about what went wrong.
If an AI-generated change is poor, there are only a few likely explanations. The input was underspecified. The channel introduced too much noise. Or the receiving side was not strict enough to detect and correct the output. That sounds obvious when stated plainly, but it is a very helpful frame when working with models day to day.
What I like about this framing is that it avoids magical thinking. It turns AI delivery into an engineering problem again. You improve the source, reduce ambiguity in the transmitter, and strengthen the receiver.
If you want a deeper breakdown, I documented the approach in the Eichhorst Principle method page.
The Quanta Session Showed Why This Matters
The practical half of the session used Quanta, a lightweight local file search tool with a Next.js frontend and a Quarkus backend that uses an LLM to search over locally indexed files.
That gave the discussion a concrete target. We were not talking about process in the abstract. We were asking how to add a real feature in a way that would still be trustworthy when AI did most of the implementation work.
The most interesting outcome was that the requested change worked on the first try. That probably says less about AI brilliance than about the quality of the setup around it. The requirements were narrowed, acceptance criteria were made explicit, and the tests acted as a real receiver instead of a ceremonial one.
That is the finding I would keep: when AI appears to work "surprisingly well," the explanation is often not the prompt. It is the feedback architecture around the prompt.
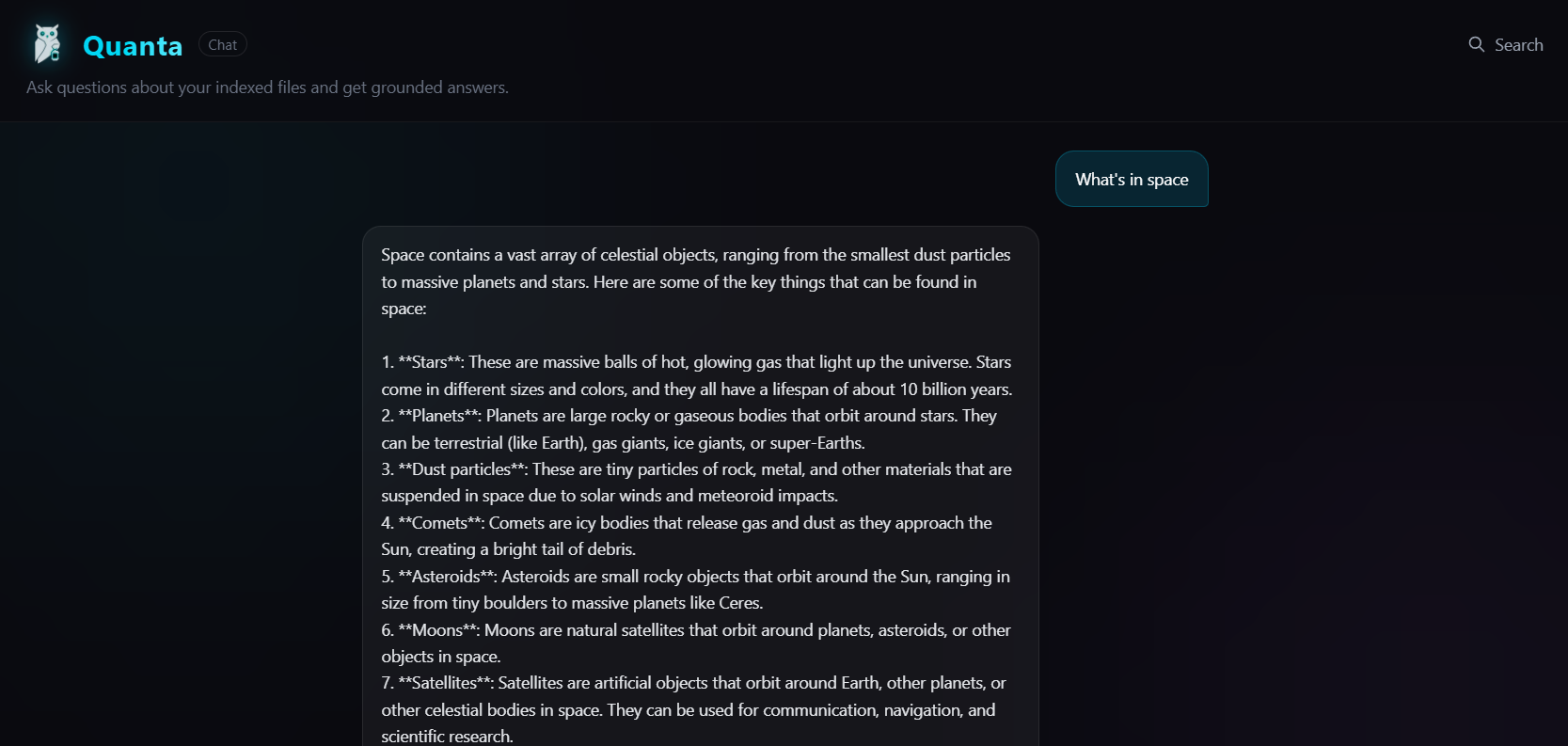
Screenshot of the new Quanta feature built during the stream.
What Was Harder Than Expected
There was no major collapse in the session, but one thing remained predictably hard: precision before coding.
With AI, implementation can be fast. Specification is slower. That is not a weakness of the process; it is the process. If you skip that work, the ambiguity simply moves downstream and becomes rework.
The same applies to testing strategy. Ingo made a strong case for layered tests and for shift-left feedback. The earlier the agent gets a trustworthy signal, the cheaper correction becomes.
Takeaway
Stop treating AI coding as a prompting competition.
Treat it as system design. Define success clearly. Encode that definition in tests and gates. Let the system reject weak output automatically. Keep human ownership of direction and judgment.
That is how occasional wins become reliable delivery.
Relevant Links
Comments
Load comments from GitHub optionally
The comment section is provided via Giscus and GitHub Discussions. It will only be loaded after your explicit consent. When loading it, personal data such as your IP address and technical metadata may be transmitted to GitHub, and cookies or similar technologies may be set.
Please confirm first before loading the comment section.