Nicht mehr nur prompten: Software Factories für Java bauen
mit Ingo EichhorstIngo Eichhorst war zu Gast und wir haben einen praktischen Software-Factory-Ansatz für Java gezeigt: erst Qualität definieren, dann klare Leitplanken setzen und KI innerhalb dieser Grenzen implementieren lassen.

YouTube
Nicht mehr nur prompten: Software Factories für Java bauen
YouTube-Video laden
Dieses Video wird von YouTube eingebettet und erst nach Ihrer Einwilligung geladen. Beim Laden können personenbezogene Daten an YouTube oder Google übermittelt und Cookies gesetzt werden.
Mehr dazu in der Datenschutzerklärung.
Projektquelle
Arbeits-Repository
Hier findest du Prompts, Instructions und Beispiele aus dem gezeigten Modernisierungs-Workflow.
Repository öffnenTimestamps der Session
- 00:00Begrüßung und Einführung
- 00:52Themenüberblick: Software Factories
- 01:01Gastvorstellung: Ingo Eichhorst
- 02:04Ingos Hintergrund und Werdegang
- 05:25Ingos Wechsel zu KI und generativen Modellen
- 06:00Frühe KI-Coding-Experimente und Tools
- 11:04Was sind Software Factories?
- 13:41Nicht-deterministische Idempotenz
- 14:09Automatisierungsansatz in der Software Factory
- 15:44Vision der Dark Factory
- 21:57Grundprinzipien von Software Factories
- 23:44Qualität in Software Factories definieren
- 27:22Einführung in das Eichhorst-Prinzip
- 31:11Shannons Theorie auf LLM-Kommunikation anwenden
- 40:36Überblick über das Ehrlicht-Projekt
- 46:15Start der Coding-Session: Quanta-Projekt
- 49:42Tests und Feedback-Mechanismen
- 55:22Anforderungen für neuen Endpoint spezifizieren
- 58:06Rückfragen mit dem LLM
- 01:00:46Diskussion zur Chat-Interface-Funktion
- 01:06:07Anforderungen in einem PRD zusammenfassen
- 01:09:28Akzeptanzkriterien erstellen und ergänzen
- 01:14:28Feature bauen und gute Git-Praktiken
- 01:25:23Gedanken zu Test-Driven Development mit LLMs
- 01:29:02Regressionstests in der KI-Entwicklung
- 01:34:09Testkosten und Strategie
- 01:35:58Docker und Projektsetup
- 01:42:44Glossar: Loop Engineering und verwandte Begriffe
- 01:51:11Integrationstests und Codebasis im Review
- 01:55:23Git Worktrees für mehrere Agenten
- 02:00:03Teststrategie: Shift Left
- 02:03:33Automatisierte Release-Tests
- 02:06:31Abschließende Gedanken zu Software Factories und KI
- 02:09:53Abschluss und Dank
KI kann schnell Code erzeugen. Die wichtigere Frage ist aber: Wie erreichen wir verlässlich gute Ergebnisse, nicht nur einen Zufallstreffer?
Genau darum ging es in dieser Session mit Ingo Eichhorst. Wir haben den Software-Factory-Ansatz für Java nicht abstrakt diskutiert, sondern praktisch angewendet: Qualität zuerst definieren, harte Leitplanken setzen und KI innerhalb dieser Grenzen arbeiten lassen.
Außerdem war es meine erste Session in Zusammenarbeit mit JUG Oberpfalz, was den Abend für mich besonders gemacht hat.

Co-Speaker
Ingo Eichhorst
AI Architect | Engineering Trainer bei IONOS
Ingo ist AI Architect und Engineering Trainer bei IONOS und Maintainer von irrlicht.io. In der Session hat er das Eichhorst-Prinzip vorgestellt und gezeigt, wie man KI-gestützte Softwareentwicklung als belastbares System aufbaut.
Von Prompting zu Factory-Denken
Der nützlichste Gedanke des Abends war nicht ein neues Tool, kein neues Modell und auch kein einzelner Prompt-Trick. Entscheidend war eine andere Frage: Worauf optimieren wir eigentlich?
Eine Software Factory will möglichst viel in der Softwareentwicklung automatisieren und trotzdem das gewünschte Ergebnis wiederholt liefern. Für KI-gestütztes Coding heißt das: weniger Hoffnung auf heroische Prompts und mehr technische Disziplin mit klaren Spezifikationen, messbaren Akzeptanzkriterien, gestuften Tests und automatisierten CI/CD-Prüfungen.
Diese Verschiebung ist wichtig, weil sie den Bewertungsmaßstab ändert. Die Frage ist nicht mehr, ob eine Antwort plausibel klingt. Die Frage ist, ob die Änderung das System um sich herum übersteht.
Quality Gates sind das eigentliche Produkt
Die Session kam immer wieder auf einen praktischen Punkt zurück: Wenn KI-gestützte Entwicklung zuverlässig werden soll, passiert die wichtigste Arbeit oft vor und nach der Generierung.
Vor der Generierung muss klar sein, wie ein gutes Ergebnis aussieht. Nach der Generierung braucht es einen Empfänger, der schwache Ausgaben automatisch zurückweist. In der Praxis ist dieser Empfänger ein Stapel aus Quality Gates: Akzeptanztests, Unit-Tests, Integrationstests, Linting und CI/CD.
Genau deshalb war diese Session nützlicher als eine beliebige Live-Coding-Demo. Sie zeigte KI nicht als autonomen Autor, sondern als Komponente in einem kontrollierten System.
Das Eichhorst-Prinzip
Der stärkste konzeptionelle Beitrag kam von Ingos Übertragung von Claude Shannons Kommunikationsmodell auf KI-gestützte Softwareentwicklung. Das Eichhorst-Prinzip gibt damit einen klaren Rahmen, um Fehlerquellen zu benennen.
Wenn eine KI-generierte Änderung schlecht ist, gibt es nur wenige wahrscheinliche Erklärungen: Die Eingabe war zu unklar. Der Kanal hat zu viel Rauschen eingebracht. Oder die Empfängerseite war nicht streng genug, um die Ausgabe zu prüfen und zu korrigieren. Genau diese Nüchternheit macht das Modell so brauchbar.
Ich mag an diesem Modell, dass es jede Magie aus der Diskussion nimmt. KI-Lieferfähigkeit wird wieder zu einem Ingenieurproblem: Quelle verbessern, Sender präzisieren, Empfänger härten.
Eine ausführliche Beschreibung findest du in meiner Methodenseite zum Eichhorst-Prinzip.
Ergebnis im Quanta-Live-Coding
Die zweite Hälfte der Session nutzte Quanta als echten Projektkontext. Quanta ist ein schlankes lokales Dateisuchwerkzeug mit einem Next.js-Frontend und einem Quarkus-Backend, das ein LLM nutzt, um über lokal indexierte Dateien zu suchen.
Dadurch blieb die Diskussion nicht abstrakt. Es ging nicht nur um Prinzipien, sondern darum, wie man in einem realen System ein neues Feature so baut, dass es auch dann vertrauenswürdig bleibt, wenn die KI den Großteil der Implementierung übernimmt.
Das interessanteste Ergebnis war, dass die gewünschte Änderung direkt im ersten Lauf funktionierte. Das spricht wahrscheinlich weniger für KI-Magie als für die Qualität des Setups darum herum. Der Umfang war eingegrenzt, die Akzeptanzkriterien waren explizit, und die Tests waren ein echter Empfänger statt bloßer Ritualhandlung.
Genau das ist das wichtigste Learning: Wenn KI "überraschend gut" funktioniert, liegt das oft nicht am Prompt, sondern an der Feedback-Architektur um den Prompt herum.
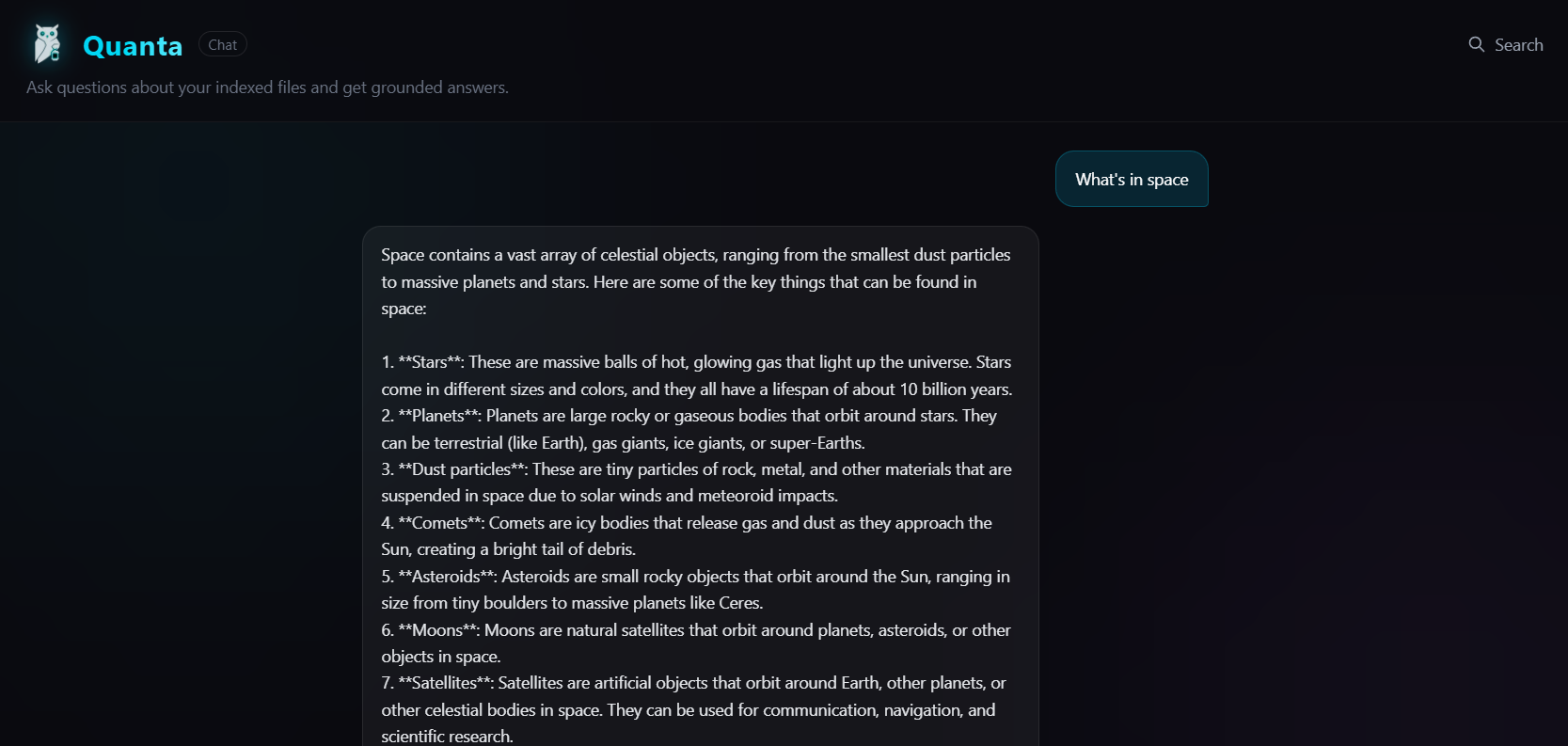
Screenshot des neuen Quanta-Features aus dem Stream.
Was schwieriger war als erwartet
Es gab keinen großen Zusammenbruch in der Session, aber eines blieb erwartbar schwierig: Präzision vor dem Coding.
Mit KI geht Implementierung oft schnell. Spezifikation geht langsamer. Das ist keine Schwäche des Prozesses, sondern der Prozess selbst. Wer diese Arbeit auslässt, verschiebt die Unklarheit nur nach hinten und bezahlt sie später als Rework.
Das Gleiche gilt für die Teststrategie. Ingo hat überzeugend für gestufte Tests und für Shift-Left-Feedback argumentiert. Je früher ein Agent ein verlässliches Signal bekommt, desto billiger wird Korrektur.
Fazit
Behandle KI-Coding nicht als Prompt-Wettbewerb.
Behandle es als Systementwurf: Zielbild definieren, Qualität codieren, schwache Ergebnisse automatisch abweisen und die menschliche Verantwortung für Richtung behalten.
So werden einzelne Erfolge zu verlässlicher Lieferung.
Nützliche Links
Kommentare
Kommentare optional von GitHub laden
Die Kommentarfunktion wird über Giscus und GitHub Discussions bereitgestellt. Sie wird erst nach Ihrer ausdrücklichen Einwilligung geladen. Beim Laden können personenbezogene Daten wie Ihre IP-Adresse und technische Metadaten an GitHub übermittelt sowie Cookies oder ähnliche Technologien gesetzt werden.
Bitte bestätigen Sie zuerst Ihre Einwilligung, bevor die Kommentare geladen werden.